Software RAID1 (starts degraded), Debian Sarge 3.1 (stable), kernel 2.6.8, GRUB
Absolutely no warranty, use entirely at your own risk, the author accepts no responsibility. It is quite likely some statements in this document are inaccurate. This HOWTO will not work on a system that uses udev. Etch and Sid use udev. This document should work on kernels 2.6.8 and older (provided the system has not migrated to udev), but will probably not work on newer 2.6 kernels. Everything considered, you have about a 1 in 3 chance this will actually work. If you should ever want to install programs from 'testing' that depend on a recent version of libc6, installing libc6 from 'testing' may remove your kernel!
Oh joy, I have a need to create a RAID1 array on an SMTP/IMAP server, and because all of our company's email will is stored on that server, I must not loose the data. I am going to use software RAID1 to mirror the hard drive and make a tape backup once each day. I experimented (on a test system) for days using bits and pieces of the many HOWTOs I found on the subject of RAID1 mirroring on Linux (and specifically Debian) and I found that there is a lot of stuff that did not work for me or is ancient history. Currently there is a another shift in the tools used that affect how RAID functions, so in a sense this document will also soon be history. I am not an expert on the subject by any means, but I have learned a few things:
If you use this document on anything but Debian Sarge 3.1, you might loose all your data.
If you don't understand the reason you are performing a step, you might loose all your data.
If you don't know exactly what will happen when you perform a step, you might loose all your data.
If you blindly copy and paste commands in this document to your shell, you might loose all your data.
If you are not paying attention and are not free from distraction, you might loose all your data.
If you have not first practiced on a test system, you might loose all your data.
If you make typo errors, you might loose all your data.
If you do not first back up your data, you might loose all your data.
If you don't perform the steps in the proper order, you might loose all your data.
If you become impatient, you might loose all your data.
If you don't document how to repair your system in the event of a hard drive failure, you might loose all your data.
Other than that, it's really pretty simple.
The easiest way to get RAID1 functionality is to configure it using the 'partman' partition manager and 'mdcfg' presented to you when you first install Debian. Of course this is only useful if you are building a new system. This document however is for a system that is currently up and running on a single drive and you wish to add a second drive to mirror the first. If you are building a new system and wish to configure your drives as a RAID1 array or are using the LILO bootloader, this document may not be for you. See http://verchick.com/mecham/public_html/raid/raid-index.html for other choices.
This document in itself is not designed to get RAID1 functional on your production computer. It is designed to get you comfortable with doing so in a test environment. The test environment you create should be as close as possible to the system you will eventually configure RAID on. A few of the steps I perform definitely should not be performed on a production system with data on it. We may do things to illustrate or prove a point; to educate us. When we finish training ourselves on a test system we should be confident enough to continue on to our production box.
My setup is on an i386 based machine. I am using the 2.6.8 kernel, the ext3 file system and the GRUB boot loader.
There is a major problem with getting RAID1 to function. The software modules that are needed to read the data from the devices in the array need to be loaded at boot time, or the devices cannot be read. The problem is, these modules are not normally included in the boot ramdisk image (/boot/initrd.img-x.x.x). For our purposes we need two modules, 'md' (multi-disk) and 'raid1' (redundant array of inexpensive/independent disks, level 1). This is very similar to the problem Windows administrators face when dealing with device drivers for hard disk controllers that are not included with Windows. You have to install the device driver on the hard drive before you install the controller, or you cannot read your hard drive. While there is evidence it may be possible, I know of no straightforward way to include the needed modules in a series of boot floppies. The bottom line is, if you cannot get the modules loaded into the ramdisk, you may not be able to boot your machine from your hard drives. Also, it is not enough to get the modules into the boot ramdisk image. Doing so will get one or two RAID devices running but the remainder depend on additional RAID software that loads later on in the boot process. In addition, you must get your system configured in such a way that BOTH hard drives are bootable so you can boot your system from either drive if the other drive has failed, or is removed. I have to admit that I don't understand (whether Windows or Linux) how the disk is read if the software needed to read the disk is on the disk! It must be some special low-level boot magic.
I suggest reading:
man initrd
I am going to talk about both SCSI and EIDE hard drives because I have tested this with both, but the examples will be SCSI. There are not a lot of differences. Simply substitute 'sda' with 'hda', 'sdb' with 'hdc' and such. Sorry, but I have not tested with SATA drives. You will need two identical hard drives to complete this project (in addition to the one currently installed in your system). They can actually be different (within reason) but if they differ in size, the smallest drive will dictate the size of the partitions, so the drives must be equal in size or larger than your current hard disk. Identical is better. Why two additional drives you say? I thought RAID1 only used two drives. True, but once you install one of the drives in your production system we want to have a spare drive available if one of the other two drives fails. That is the point isn't it? Besides, we are going to use the two spare drives as test drives prior to installing one of them in the production machine.
Name your hard drives so it is easier for me to refer to them. Actually label these names on them. Name one of them apple, and one of then pie. If one of the drives is smaller than the other, label the smaller of the two apple. For an EIDE system, one drive must be installed on the primary master drive connector and the other on the secondary master drive connector. I am going to refer to the EIDE drive that is connected to the primary master connector as being in the primary position. Linux should recognize this drive as /dev/hda. I am going to refer to the EIDE drive that is connected to the secondary master connector as being in the secondary position. Linux should recognize this drive as /dev/hdc.
For a SCSI system with both drives on one SCSI adapter, one drive should be configured as SCSI device id 0 (on my system removing all ID jumpers on the drive sets it to 0), and the other drive is typically configured as SCSI device id 1 (I add a jumper to the drive to set this). I am going to refer to the SCSI drive that is configured as SCSI device id 0 as being in the primary position. Linux should recognize this drive as /dev/sda. I am going to refer to the SCSI drive that is configured as SCSI device id 1 as being in the secondary position. Linux should recognize this drive as /dev/sdb. These statements assume both drives are installed. If only one drive is installed, it will be in the primary position and be recognized as /dev/sda regardless of the jumper setting.
For a SCSI system with each drive on separate SCSI adapters, both drives are typically configured as SCSI device id 0 (but I prefer to set the one on the second adapter as SCSI device id 1). You may need to determine which adapter is recognized first and which is recognized second. If the adapters are the same model by the same manufacturer this is a more difficult task. You may have to temporarily remove one of the drives to see which adapter is recognized first. Then you may want to label them. I am going to refer to the SCSI drive that is on the adapter that is recognized first as being in the primary position. Linux usually recognizes this drive as /dev/sda. I am going to refer to the SCSI drive that is on the adapter that is recognized second as being in the secondary position. Linux should recognize this drive as /dev/sdb. These statements assume both drives are installed. If only one drive is installed, it will be in the primary position and be recognized as /dev/sda regardless of which adapter it is installed on.
All the data on the two drives we use for testing will be erased. Any drive that may be used in the future to replace a drive that has failed MUST be clean. Any drive that has been used in a RAID array at any time in the past must also be cleaned. Let me explain why. Let's pretend for a moment that we used apple in a RAID array, then unplugged it and replaced it, then put it away for later use as an emergency replacement. A year from now one of our drives goes bad, so we shut the machine down and place apple in its place. Then we boot up and to our horror, the good drive has synced itself to the data stored on apple and not the other way around. To clean a drive, install it in a system by itself, and boot up using a DBAN disk. You can change the method to Quick erase. This will write zeros to each bit on the disk. You should also have a tomsrtbt disk (or other suitable rescue disk) available.
Install a cleaned apple in the primary position and leave pie out of the computer. A good place for the CDROM drive is the secondary slave EIDE interface. Boot up using the appropriate Debian installer media. I use the stable netinst CD.
Install kernel 2.6 by using 'linux26' at the initial installation screen. If your production system is using the 2.4 kernel then you should install that instead (linux instead of linux26).
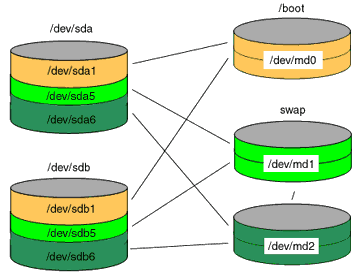
This illustration shows what the end product of my test machine will look like. Some people use a separate /boot partition and I have only tested this setup with one in place. When installing Debian on your system you should set the partitions up in the same manner as your production box so you can gain experience with something closer to your setup. I will not detail installing Debian, but I will say that since this is just a test system you will only need to install the absolute minimum number of software packages. When using the partition manager you do not want to configure RAID in any way. You should install the GRUB boot loader. Please take notes on how your disk is configured:
device mount md-device temp-mount boot partition-type /dev/sdb1 /boot /dev/md0 /mnt/md0 * primary /dev/sdb5 swap /dev/md1 logical /dev/sdb6 / /dev/md2 /mnt/md2 logical
Continue on with the Debian installer until you get to the point you can log in as root.
If you need a tomsrtbt disk, insert a blank floppy, then:
cd /usr/local/src
wget http://ftp.sunsite.utk.edu/ftp/pub/mini-linux/tomsrtbt/tomsrtbt-2.0.103.tar.gz
tar xzvf tomsrtbt-2.0.103.tar.gz
rm tomsrtbt-2.0.103.tar.gz
cd tomsrtbt-2.0.103
./install.s
You may also be able to Google for an iso image that you can use to create a bootable tomsrtbt CD. Now you can remove apple, install pie in its place and clean it per the instructions mentioned earlier. Then place apple back in the primary position and place pie in the secondary position.
Back up a few files. Your initrd.img may be a different version. If so, I suggest saving this document to your computer and doing a search and replace of the kernel version number:
cp /etc/fstab /etc/fstab-backup
cp /etc/mtab /etc/mtab-backup
cp /etc/mkinitrd/modules /etc/mkinitrd/modules-backup
cp /etc/modules /etc/modules-backup
cp /etc/mkinitrd/mkinitrd.conf /etc/mkinitrd/mkinitrd.conf-backup
cp /boot/grub/menu.lst /boot/grub/menu.lst-backup
cp /boot/initrd.img-2.6.8-2-386 /boot/initrd.img-2.6.8-2-386-backup
I personally need my vim, and we need to install our main program, mdadm (multi-disk administrator). Obviously you may choose to use a different editor. When installing mdadm it is imperative you answer [YES] to both questions: Do you want to start the RAID devices automatically? and Do you want to start the RAID monitor daemon?
apt-get update
apt-get install vim initrd-tools mdadm
cat /etc/default/mdadm
Should show something like:
# This file is automatically generated.
# Run 'dpkg-reconfigure mdadm' to modify it.
START_DAEMON=true
MAIL_TO="root"
AUTOSTART=true
Now we will include the needed modules in the ramdisk image. We start by modifying a file that the compiler uses:
vim /etc/modules
and insert at the end of the list of modules:
md
raid1
raid5
xor
raid0
Save and exit the file. This part is important to get right or our system will not boot. You need to copy all the modules listed in /etc/modules to /etc/mkinitrd/modules that deal with our hard disk drives, motherboard chipset and raid (in the same order thay are listed in /etc/modules). You would not need to include drivers (modules) that obviously deal with things like the CDROM drive or mouse. If you are not certain, then it is better to include it. If our hard drives are not recognized prior to our md devices, our system will not boot. You might see modules like 'ide-detect', 'ide-disk', 'ide-scsi' and others. Essentially copy all the modules to /etc/mkinitrd/modules, then remove any that do not pertain to our hard drives (psmouse, ide-cd):
grep -vE '^$|^#' /etc/modules >> /etc/mkinitrd/modules
vim /etc/mkinitrd/modules
Once you have added (and possibly removed) modules there, save and exit the file. Now we make the new initrd.img. We actually end up doing this three or four different times during this setup (because our system will be going through changes). The mkinitrd program may not want to directly replace the file we are using, so we compile to a temporary file, then copy it over the top of our current initrd.img. As noted before, edit this to reflect your system if needed.
mkinitrd -o /boot/initrd.img-2.6.8-2-386-temp /lib/modules/2.6.8-2-386/
cp /boot/initrd.img-2.6.8-2-386-temp /boot/initrd.img-2.6.8-2-386
In order to load the new image into memory, we must reboot:
reboot
When the system comes back up run 'cat /proc/mdstat' to see if we now have a system capable of using a RAID array:
cat /proc/mdstatThe resulting output on my machine:
Personalities : [raid0] [raid1] [raid5]
unused devices: <none>
If [raid1] is not shown here then you are not loading the needed modules.
You cannot continue past this point until you are.
Now we will copy the partition structure from apple to pie. This is one of those things you must be careful doing because this will destroy all data on the target disk. Since we have already cleaned the target disk we should not have to --force this to work. The target disk must be of equal or greater size than the source disk. Make sure the command reflects what you want to accomplish:
Run 'df' to first make sure we are currently using the disk you think we are:
df
Here we copy the structure from /dev/sda to /dev/sdb:
sfdisk -d /dev/sda | sfdisk /dev/sdb
Now we will use cfdisk to edit the partition table on pie (in the secondary position) and change the partition types to "Linux raid autodetect". This may also destroy all data on a disk so be careful you are editing the correct disk. To change the partition type, first use up and down arrows to select a partition, then left and right arrows to select [Type] from the menu. Press [Enter] to change the type. The type you want is 'FD' (lower case is fine). Repeat for all partitions, then [Write] the changes, then [Quit]. Your original drive should have had a partition flagged as bootable that was copied to this target drive. Make sure you don't accidentally toggle this off.
cfdisk /dev/sdb
My finished product:
cfdisk 2.12p
Disk Drive: /dev/sdb
Size: 18200739840 bytes, 18.2 GB
Heads: 255 Sectors per Track: 63 Cylinders: 2212
Name Flags Part Type FS Type [Label] Size (MB)
------------------------------------------------------------------------------
sdb1 Boot Primary Linux raid autodetect 296.12
sdb5 Logical Linux raid autodetect 501.75
sdb6 Logical Linux raid autodetect 17396.47
At this point we will reboot again so our system properly recognizes the changes
made to this disk:
reboot
Now we can start the process of creating the degraded array. We start by doing some additional cleaning of our drive in the secondary position (pie). This is to insure there are no remnants from prior RAID installations. Zero the superblock for each of the partitions we configured as type "Linux raid autodetect":
mdadm --zero-superblock /dev/sdb1
mdadm --zero-superblock /dev/sdb5
mdadm --zero-superblock /dev/sdb6
Now we create md devices for each of our partitions, with one partition present on each md device and one partition missing. The ones that are missing are on our primary drive (apple). We can't add these to our array at this time because those partitions are currently in use and they are not the of the type of partition we want. The general plan is to create the RAID structure on the first RAID disk (pie), copy all the data from the original disk (apple) to that RAID disk, reboot to that degraded RAID disk, then reformat the original disk and add it to our RAID array (at which time the two disks will begin to synchronize). There are obvious risks in doing this and the process is prone to error. One thing that could be difficult to keep track of is: a number of files related to RAID must of course be on the RAID drive. When we boot to the RAID drive, it must be configured as a RAID drive. Some people first copy all the data from the original drive to the RAID drive, then modify the RAID related files on the RAID drive prior to rebooting into it. Then if they have problems and need to make changes to the system they often make the mistake of trying to fix the RAID related files by editing the files on the original drive. I prefer to configure everything on the original drive and then copy the data over at the very last moment. If things get really ugly we can boot up with the tomsrtbt disk and make a few changes to the original disk to enable us to boot up into it (provided we have not reformatted it yet). Then we can make the necessary changes and copy the data over once again. Anyway, lets create the needed md devices. Edit as required and then run these one at a time:
mdadm --create /dev/md0 --level=1 --raid-disks=2 missing /dev/sdb1
mdadm --create /dev/md1 --level=1 --raid-disks=2 missing /dev/sdb5
mdadm --create /dev/md2 --level=1 --raid-disks=2 missing /dev/sdb6
If you get "No such file or directory" errors, you are probably using a 2.6.x kernel which is using udev and initramfs-tools (or yaird) instead of devfs/hotplug and initrd-tools. This document does not support udev. Sorry, but I have yet to get a degraded RAID installation to work on such a system. I have been able to repair a system that was once fully functional under devfs and initrd-tools and then was inadvertently upgraded to a 2.6.15 kernel (I show how later) but I'm not sure if a system like that is fully functional and you may not have the same luck I did. The only reason it worked is because the system did not migrate to udev.
Once again, run 'cat /proc/mdstat':
cat /proc/mdstat
You should get something similar to this which displays the fact that one out of two disk devices are up [_U] for each of our md devices (and the other ones are missing). This is called 'degraded':
Personalities : [raid0] [raid1] [raid5]
md2 : active raid1 sdb6[1]
16988608 blocks [2/1] [_U]
md1 : active raid1 sdb5[1]
489856 blocks [2/1] [_U]
md0 : active raid1 sdb1[1]
289024 blocks [2/1] [_U]
You may see a different format:
Personalities : [raid0] [raid1] [raid5]
read_ahead 1024 sectors
md2 : active raid1 scsi/host0/bus0/target1/lun0/part6[1]
16988608 blocks [2/1] [_U]
md1 : active raid1 scsi/host0/bus0/target1/lun0/part5[1]
489856 blocks [2/1] [_U]
md0 : active raid1 scsi/host0/bus0/target1/lun0/part1[1]
289024 blocks [2/1] [_U]
"target 1" here is our secondary drive (/dev/sdb), so "target 1, part6" would be the same as /dev/sdb6.
If your system does not show something with a structure similar to one of the two above,
then you must fix it before continuing.
Now we create file systems on our md devices that match the file systems
currently in use on our original devices. This also erases data on the target
devices. I use ext3 and of course a swap partition:
mkfs.ext3 /dev/md0
mkswap /dev/md1
mkfs.ext3 /dev/md2
When the system boots up into our RAID system, it should automatically assemble at least one of the md devices we created (so we can start the boot process) but it may not assemble the rest. This could result in a failure to complete to boot process. This task of reassembling the remaining devices is handled by /etc/init.d/mdadm-raid. This init script uses the command 'mdadm -A -s -a' which means: "automatically assemble all of our md devices using the information stored in /etc/mdadm/mdadm.conf". Well, we must update the information in mdadm.conf so it correctly reflects our current state (as shown by /proc/mdstat). To do so:
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
Now let's display the file this created:
cat /etc/mdadm/mdadm.conf
It should show something like this. Newer versions of mdadm will not have the "devices" lines:
DEVICE partitions
ARRAY /dev/md2 level=raid1 num-devices=2 UUID=6f5d3fff:caeafab8:0cfbc28d:e45f0958
devices=/dev/sdb6
ARRAY /dev/md1 level=raid1 num-devices=2 UUID=76655a65:891fab10:bbca9c0b:c4b629ec
devices=/dev/sdb5
ARRAY /dev/md0 level=raid1 num-devices=2 UUID=7cb5650b:0d0c9505:94ffb265:c052450f
devices=/dev/sdb1
Our RAID system has changed, so once again we are going to make a new initrd.img:
rm /boot/initrd.img-2.6.8-2-386-temp
mkinitrd -o /boot/initrd.img-2.6.8-2-386-temp /lib/modules/2.6.8-2-386/
cp /boot/initrd.img-2.6.8-2-386-temp /boot/initrd.img-2.6.8-2-386
Before we attempt booting up into our md devices we are first going to do a test to insure our md devices are assembled after a reboot and that they are mountable during the boot process. First we make a mount point for each of our devices (all except the swap partition):
mkdir /mnt/md0
mkdir /mnt/md2
Run 'free' and make a note of how much total swap space you have:
free
Then edit /etc/fstab and make some changes. At the bottom of the file place directives to mount each of our md devices to the mount points we created (or swap). Here is a sample:
vi /etc/fstab
and insert at the bottom of the current settings (edit as needed to reflect your system):
/dev/md0 /mnt/md0 ext3 defaults 0 0 /dev/md1 none swap sw 0 0 /dev/md2 /mnt/md2 ext3 defaults 0 0With these lines added my /etc/fstab now looks like this:
proc /proc proc defaults 0 0 /dev/sda6 / ext3 defaults,errors=remount-ro 0 1 /dev/sda1 /boot ext3 defaults 0 2 /dev/sda5 none swap sw 0 0 /dev/hdd /media/cdrom0 iso9660 ro,user,noauto 0 0 /dev/fd0 /media/floppy0 auto rw,user,noauto 0 0 /dev/md0 /mnt/md0 ext3 defaults 0 0 /dev/md1 none swap sw 0 0 /dev/md2 /mnt/md2 ext3 defaults 0 0Save and exit the file, then let's reboot and see if this works:
reboot
When the system comes up, run 'mount' to see if the devices were mounted.
There is no point continuing past this point unless they were:
mount
If you run 'free' again, it should show the total swap space is twice the size it was before.
Assuming you have a swap partition, you must get this working before you continue on:
free
Then run 'cat /proc/mdstat' again and verify all the md devices that used to be there are still there.
There is no point continuing past this point unless they are:
cat /proc/mdstat
OK. If everything is working (it must be working before you continue), now comes the scary part. Don't reboot until I tell you to. We are going to continue to configure RAID related files on our original drive, then we are going to copy all our data from the original devices to the md devices, then create a boot record on the secondary drive, then boot up using the md devices on the secondary drive instead of our original devices on the primary drive. There are a few things to think about as far as the copy process goes. The machine should not be in the middle of processing stuff, so you should drop into single user mode and possibly disconnect the ethernet cable. Because you will be in single user mode you will run the actual copy commands at the console (not remotely). You should not delay once the data is transferred and it comes time to reboot. If you successfully boot up into the md devices then be aware that the data on the original drive will soon become stale, so in the event you need to boot back into the original drive be aware that you may loose data. Hopefully you will have no need to do that and your new RAID devices will hold current data from now on. If you are able to boot up using your md devices, the scary part is over (but opportunities to destroy your system still remain). We are going to configure /etc/fstab to boot up into the md devices; we are going to create another initrd.img that knows about our md devices and we are going to tell grub to boot into our md devices. We will also configure grub to boot from our secondary drive. We will start by editing /etc/fstab again. We must remove (or comment out) the lines we added previously (they were just a test), then change the corresponding /dev/sda devices in /etc/fstab to /dev/md devices.
vi /etc/fstab
and modify it in a similar manner to this sample. Of course the mount points must correctly correspond to appropriate md devices. Refer to the notes you should have made. My finished /etc/fstab file will look like this:
proc /proc proc defaults 0 0 /dev/md2 / ext3 defaults,errors=remount-ro 0 1 /dev/md0 /boot ext3 defaults 0 2 /dev/md1 none swap sw 0 0 /dev/hdd /media/cdrom0 iso9660 ro,user,noauto 0 0 /dev/fd0 /media/floppy0 auto rw,user,noauto 0 0Modify another file that mkinitrd uses, mkinitrd.conf:
vi /etc/mkinitrd/mkinitrd.conf
and replace the ROOT=probe entry to an entry that reflects the md device that root (/) will be mounted on, and the file system in use there:
#ROOT=probe
ROOT="/dev/md2 ext3"
Note that you may also want to change MODULES=most to MODULES=dep. Doing so will make your initrd.img about half its original size. I don't know what other implications there may be in doing this. I do not know if this will adversely affect your system so use at your own risk. Actually, you are doing all of this at your own risk.
Once again we would update our initrd.img:
rm /boot/initrd.img-2.6.8-2-386-temp
mkinitrd -o /boot/initrd.img-2.6.8-2-386-temp /lib/modules/2.6.8-2-386/
cp /boot/initrd.img-2.6.8-2-386-temp /boot/initrd.img-2.6.8-2-386
Now we are going to update the GRUB menu. Edit grub's menu.lst:
vi /boot/grub/menu.lst
We are going to add a new menu item that tells grub to boot from our secondary drive (grub refers to it as hd1). We will also add a fallback entry that (hopefully) will automatically choose the next item in the menu if the first item fails. So, just below "default 0", add this entry:
fallback 1
Make a duplicate of your existing top menu stanza, place the duplicate above the existing stanza and modify it in the same manner I have. I changed hd0 to hd1 and /dev/sda6 to /dev/md2. This example shows partition 0 is the partition flagged as bootable on my system. You can run something like 'fdisk -l /dev/sda' to determine which partition is bootable on your system but your original stanza will be correct. Remember that grub starts counting from zero:
title Debian GNU/Linux, kernel 2.6.8-2-386 RAID (hd1) root (hd1,0) kernel /vmlinuz-2.6.8-2-386 root=/dev/md2 ro initrd /initrd.img-2.6.8-2-386 savedefault boot title Debian GNU/Linux, kernel 2.6.8-2-386 root (hd0,0) kernel /vmlinuz-2.6.8-2-386 root=/dev/sda6 ro initrd /initrd.img-2.6.8-2-386 savedefault bootJust a note: because we mount a /boot partition, you will not see the above entries in the form "/boot/initrd.img-2.6.8-2-386". If you do not mount a /boot partition, you will see the entries in that form.
If you have been following this HOWTO correctly, our md devices will still be mounted to the mount points we had in /etc/fstab when we booted up. If they are not mounted for some reason (shame on you, I told you not to reboot), you will need to remount them. For example: "mount /dev/md2 /mnt/md2", "mount /dev/md0 /mnt/md0". Now we are going to copy our data. In my case I want to copy all the data in the root partition to /mnt/md2, and all the data in the /boot partition to /mnt/md0. The copy from root to the md mount point is straightforward but other mount points such as /boot are not as straightforward. For those I first change to that directory, then use the period (.) to signify "here". In other words "copy from here to there" as opposed to "copy this to that". The prevents me from copying /boot to /mnt/md0 and ending up with a /mnt/md0/boot directory instead of a /mnt/md0 directory containing all the files in the /boot directory.
At the console get into single user mode:
init 1
then work on the copy process. All files on the disk need to get copied so use your head:
cp -dpRx / /mnt/md2
cd /boot
cp -dpRx . /mnt/md0
Run some tests and make sure the source and destination match for each mount point.
Fix it if they don't:
ls -al /
ls -al /mnt/md2
ls -al /boot
ls -al /mnt/md0
On my system grub was booting off of hard disk 0, partition 0, and it was told root was mounted on /dev/sda6. Now I have instructed it to boot off of hard disk 1, partition 0, and I told it root is mounted on /dev/md2. Now I must install grub on hard disk 1, partition 0 (the secondary drive). Start the grub shell prompt:
grub
at the grub> prompt enter these commands to install grub on both drives (edit partition number if needed):
root (hd0,0)
setup (hd0)
root (hd1,0)
setup (hd1)
quit
OK. Now comes the butterflies in your stomach.
Knock on wood, throw salt over your shoulder, rub your lucky rabbit's foot, cross your fingers.
reboot
If it crashes, don't freak out just yet. Read this. If it reboots, run 'df' and check that it is in fact our md devices we are using. Run 'cat /proc/mdstat' again and insure all md devices are shown there, If all is well, we are no longer using the original drive. If all is not well, it must be fixed before we continue:
df
cat /proc/mdstat
My df looked like this:
Filesystem 1K-blocks Used Available Use% Mounted on /dev/md2 16721716 385720 15486568 3% / tmpfs 258208 0 258208 0% /dev/shm /dev/md0 279891 23846 241594 9% /bootOK. Now we will reformat the original drive (apple /dev/sda) and then add it to our array. I hope everything is working great so far and all our files were successfully copied because we now must destroy all data on the original drive. Run cfdisk on the original drive and (just as we did for our secondary drive) change the type of each partition to type "FD". This is the part where (if you are working on a production box) you should have a good backup of the drive because this will destroy all the data on the original disk:
cfdisk /dev/sda
Change all the partition types, then write and quit. Make sure you have not toggled off the boot flag.
Now we can add the partitions on /dev/sda to our RAID array. Edit this to suit your system. Do this one at a time:
mdadm --add /dev/md2 /dev/sda6
mdadm --add /dev/md0 /dev/sda1
mdadm --add /dev/md1 /dev/sda5
Now you will just have to WAIT until the disks synchronize. NEVER REBOOT while disks are synchronizing.
You can monitor the progress with:
watch -n 6 cat /proc/mdstat
Mine looks like this after a while. Notice we now are using both drives and md2 has fully synced:
Personalities : [raid0] [raid1] [raid5]
md0 : active raid1 sda1[2] sdb1[1]
289024 blocks [2/1] [_U]
[=>...................] recovery = 6.7% (19520/289024) finish=0.2min speed=19520K/sec
md1 : active raid1 sda5[2] sdb5[1]
489856 blocks [2/1] [_U]
resync=DELAYED
md2 : active raid1 sda6[0] sdb6[1]
16988608 blocks [2/2] [UU]
unused devices: <none>
Of course, it's [Ctrl]+c to cancel 'watch'. Once the sync has completed (and not until then), we need
to tell mdadm.conf about our new drives and make another initrd.img (for the last time):
echo "DEVICE partitions" > /etc/mdadm/mdadm.conf
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
This should now show all our devices are present:
cat /etc/mdadm/mdadm.conf
For the last time:
rm /boot/initrd.img-2.6.8-2-386-temp
mkinitrd -o /boot/initrd.img-2.6.8-2-386-temp /lib/modules/2.6.8-2-386/
cp /boot/initrd.img-2.6.8-2-386-temp /boot/initrd.img-2.6.8-2-386
We need to edit grub's menu.lst one last time. We are booting off of the secondary drive (and will continue to do so) but now if that should fail we want it to boot off the primary drive (now also configured as a RAID device). Make a copy of the first menu choice stanza, place it in the second position, and modify it in a manner similar to the provided sample:
vi /boot/grub/menu.lst
title Debian GNU/Linux, kernel 2.6.8-2-386 RAID (hd1) root (hd1,0) kernel /vmlinuz-2.6.8-2-386 root=/dev/md2 ro initrd /initrd.img-2.6.8-2-386 savedefault boot title Debian GNU/Linux, kernel 2.6.8-2-386 RAID (hd0) root (hd0,0) kernel /vmlinuz-2.6.8-2-386 root=/dev/md2 ro initrd /initrd.img-2.6.8-2-386 savedefault bootWhile you are at it, modify the '# kopt=root=' line to reflect our current situation (I changed /sda6 to /md2).
Don't remove the # in front of it, it has meaning. (double ## are comments in this special AUTOMAGIC section):
# kopt=root=/dev/md2 ro
Also, if everything is working properly you should remove the menu stanza that boots to a non-raid partition. You would corrupt your system if you were to boot up to something like /dev/sda6 and edit files on that drive.
Your system is complete. I would reboot one more time just to make sure it comes up.
OK, now I'm going to simulate a failed drive. I don't recommend you try this (your system may explode), but at least you can learn from my system. I am carefully going to remove the power cable from the primary drive, apple. Once I do this, it will be "dirty" and should not be used again in this system without first being cleaned. This is what mdstat shows as a result: sda1 and sda5 still show they are up because we have not had any read/write operations on them recently, sda6 shows it has failed (Faulty).
md0 : active raid1 sda1[0] sdb1[1]
289024 blocks [2/2] [UU]
md1 : active raid1 sda5[0] sdb5[1]
489856 blocks [2/2] [UU]
md2 : active raid1 sda6[2](F) sdb6[1]
16988608 blocks [2/1] [_U]
If your hardware supports hot swappable drives I think you should mark
the remaining two devices faulty (since they actully are on a failed drive),
then use mdadm to remove all three faulty devices
from our array before inserting the new drive. You cannot use "mdadm --remove" on
devices that are in use, so they need to be set as faulty first.
You do not need to do this if you are going
to power down the system and replace the drive with a clean drive.
Make doubly sure you are failing the partitions on the
drive that has failed!
Only needed if using hot-swap drives and you are not going to power down:
mdadm --set-faulty /dev/md0 /dev/sda1
|
Shut it down:
shutdown -h now
For consistency (and to keep my sanity) I always move the good drive to the primary position (if it is not already there) and place the new clean drive in the secondary position. We have shut down, so disconnect the good drive, clean apple, move pie (the good drive) into the primary position, place the cleaned apple in the secondary position and bring the system back up. On my system all I have to do to swap the two SCSI drives is move the jumper from one drive to the other. OK, my system did boot up.
First we see what's going on (cat /proc/mdstat). As you can see, sdb1, sdb5 and sdb6 are missing:
md0 : active raid1 sda1[1]
289024 blocks [2/1] [_U]
md1 : active raid1 sda5[1]
489856 blocks [2/1] [_U]
md2 : active raid1 sda6[1]
16988608 blocks [2/1] [_U]
We start by copying the partition structure from /dev/sda to /dev/sdb. We
do this for what should now be an obvious reason: the secondary drive is empty, but
it needs to have the same structure as the primary drive. If the disk was first
cleaned, and is large enough, you should have no errors:
sfdisk -d /dev/sda | sfdisk /dev/sdb
We make sure the superblocks are zeroed out on the new drive (as always, be careful you do this to the correct drive). Edit as needed:
mdadm --zero-superblock /dev/sdb1
mdadm --zero-superblock /dev/sdb5
mdadm --zero-superblock /dev/sdb6
Now we add our three sdb partitions to the corresponding md's.
Understand what you are doing here before you do it, edit as needed:
mdadm --add /dev/md0 /dev/sdb1
mdadm --add /dev/md1 /dev/sdb5
mdadm --add /dev/md2 /dev/sdb6
Watch them sync:
watch -n 6 cat /proc/mdstat
Once the recovery is complete (and not until then), create a new boot records on both drives:
grub
From the grub> prompt (edit partition number if needed):
root (hd0,0)
setup (hd0)
root (hd1,0)
setup (hd1)
quit
We are working again.
You might want to reboot from the console to make sure you actually boot from the secondary drive.
You should never try this next step on a production system because it will trash your array. You need to prove to yourself that each drive will boot up when it is the only drive in the system so you should boot up using each drive with the other one missing. As soon as a drive boots up, log in and run 'shutdown -h now' to shut it back down. Then try the other drive. Then if you care in the least about the integrity of the data on the system you should clean one of the drives and install it just as you would if you were replacing a failed drive. It's not a good idea to fire up the system using both drives if each drive has been started independently.
In A RAID system it is a good idea to avoid kernel version upgrades (security upgrades should be performed of course). Installing a kernel newer than 2.6.8 may replace devfs with udev. If this happens you could be in big trouble. I have not been able to repair a system once it migrates from devfs to udev. Some of the new 2.6 kernels (from 2.6.12) no longer use mkinitrd to create the initrd.img. The set of programs now used to create the ramdisk image (initramfs-tools - run 'man mkinitramfs') for some reason may not create an initrd.img that is able to boot into our md devices. As a result, after an upgrade to one of the newer kernels, your system may not boot to the new kernel. This bug may be resolved at some point in the future (and may be resolved when you read this) but to work around the problem I was able to use mkinitrd to create the ramdisk image. The use of mkinitrd is deprecated when used with kernels 2.6.12 or newer. I don't know why this worked for me. I would not be surprised if it does not work for you. I am using Sarge but as a test I will install a kernel from 'testing' (Etch) to illustrate.
I installed a 'testing' source in /etc/apt/sources.list and ran 'apt-get update'. We need a newer version of initrd-tools that can be used with the newer kernel:
apt-get -t testing install initrd-tools
Now I determine the correct kernel for my architecture:
apt-cache search linux-image
I am going to install:
apt-get install linux-image-686
Running this command installed version 2.6.15-1-686 on my system. At this point the kernel may not boot into our md devices. You can try if you like to see if the bug has been fixed. If not then you will have to boot up using the old kernel. Then we will again compile a new /boot/initrd.img using mkinitrd:
cp /boot/initrd.img-2.6.15-1-686 /boot/initrd.img-2.6.15-1-686-backup
mkinitrd -o /boot/initrd.img-2.6.15-1-686-temp /lib/modules/2.6.15-1-686/
cp /boot/initrd.img-2.6.15-1-686-temp /boot/initrd.img-2.6.15-1-686
We are now going to reconfigure grub once again:
vi /boot/grub/menu.lst
Make a duplicate of your existing top menu stanza, place the duplicate above the existing stanza and modify it in the same manner I have (so we boot off of hd1):
title Debian GNU/Linux, kernel 2.6.15-1-686 (hd1) root (hd1,0) kernel /vmlinuz-2.6.15-1-686 root=/dev/md2 ro initrd /initrd.img-2.6.15-1-686 savedefault boot title Debian GNU/Linux, kernel 2.6.15-1-686 (hd0) root (hd0,0) kernel /vmlinuz-2.6.15-1-686 root=/dev/md2 ro initrd /initrd.img-2.6.15-1-686 savedefault bootSave and exit the file, then start up the grub command prompt:
grub
at the grub> prompt enter these commands to reinstall grub on both drives (edit partition number if needed):
root (hd0,0)
setup (hd0)
root (hd1,0)
setup (hd1)
quit
Reboot to make sure it works.
References (alphabetical order). Not all of these are good, but all were interesting to me in one way or another. Trust me, there are a lot more documents similar to these out there:
http://alioth.debian.org/project/showfiles.php?group_id=30283&release_id=288
http://deb.riseup.net/storage/software-raid/
http://forums.whirlpool.net.au/forum-replies-archive.cfm/471585.html
http://nepotismia.com/debian/raidinstall/
http://nst.sourceforge.net/nst/docs/user/ch14.html
http://piirakka.com/misc_help/Linux/raid_starts_degraded.txt
http://thegoldenear.org/toolbox/unices/server-setup-debian.html
http://togami.com/~warren/guides/remoteraidcrazies/
http://www.debian-administration.org/articles/238
http://www.debian-administration.org/users/philcore/weblog/4
http://www.doorbot.com/guides/linux/x86/grubraid/
http://www.epimetrics.com/topics/one-page?page_id=421&topic=Bit-head%20Stuff&page_topic_id=120
http://www.james.rcpt.to/programs/debian/raid1/
http://www.linuxjournal.com/article/5898
http://www.linuxsa.org.au/mailing-list/2003-07/1270.html
http://www.linux-sxs.org/storage/raid_setup.html
http://www.parisc-linux.org/faq/raidboot-howto.html
http://www.tldp.org/HOWTO/Software-RAID-HOWTO.html
http://trinityhome.org/misc/bootable-raid1.html
http://www.vermittlungsprovision.net/367.html
http://xtronics.com/reference/SATA-RAID-debian-for-2.6.html